|
http://www.econport.org
Copyright © 2006 Experimental Economics Center, Georgia State University. All rights reserved.
|
|
|
|
Why Free Ride? Strategies and Learning in Public Goods Experiments |
|
James Andreoni in "Why Free Ride? Strategies and Learning in Public Goods Experiments," Journal of Public Economics 37, 1988, pp. 291-304, article investigates why free riding is seldom observed in single-shot games but is often approximated in finitely repeated games. He designs a VCM experiment to examine two explanations of such behavior: strategies and learning. |
|
Hypotheses |
|
The experimental literature on free riding reports three consistently replicated observations:
|
|
Free Riding Hypothesis |
|
Learning Hypothesis |
|
Strategies Hypothesis |
|
Strategic Behavior Example: |
|
Experimental Design and Procedures |
|
Andreoni designed this VCM experiment to separate the learning from strategic play. His design is subtractive: "...subjects participate in a repeated-play environment, but are denied the opportunity to play startegically. Without strategic play, we can isolate the learning hypothesis. Furthermore, by comparing this group to one that can play strategically, we can attribute the difference, if any, to strategic play." (Andreoni [1987], pp. 294) |
|
Strangers |
|
Partners |
|
Payoffs |
|
Discriminating Between the Learning and Strategies Hypotheses |
|
Suppose a subject is initially contributing a positive amount towards the public good, but in some period t she learns that free riding is a single-shot [LINK dominant strategy]. If she is a Partner and plays strategically, she might have an incentive to continue contributing. However, if she is a Stranger, there is no reason for her to invest in the public good since every game is the end-game for her. Therefore, under the strategic hypothesis, it is expected that Partners will be contributing more than Strangers, especially early in the game before the Partners start to decrease their contributions because of the game-end effect. In the last round, both groups are predicted to free ride. |
|
To isolate the learning effect, the experimental design included a restart followed by three rounds of play. Partners were told they would stay in the same group, while Strangers would continue to be randomly reassigned as before. Under the learning hypothesis, both Partners and Strangers should not be affected by the restart. If behavior of either group would change, it would imply that learning itself is not primarely responsible for decay. |
|
Experimental Results and Possible Explanations of Observed Behavior |
|
|
|
|
|
|
|
|
|
|
|
|
Observations |
|
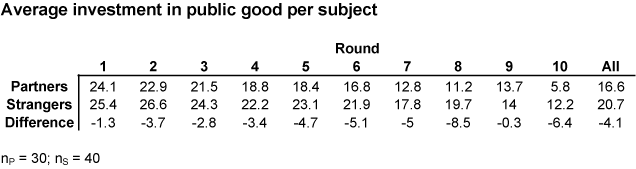
Observation 1. Contributions by Partners are significantly smaller than contributions by Strangers in all 10 rounds and the difference grows as the last round approaches. This is exactly the opposite to the strategies hypothesis indicating that giving by Partners should be greater in all rounds with the difference getting smaller towards the end of the game. |
|
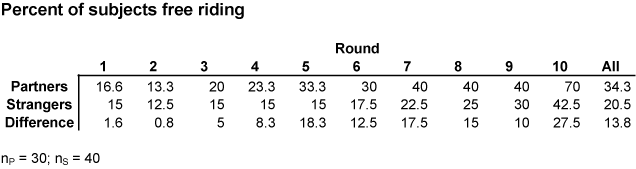
Observation 2. In all 10 rounds the percent of free riding Partners is greater than the percent of free riding Strangers. The difference is greatest in the last round and is statistically significant. This opposes the strategies hypothesis. |
|
Observation 3. The contributions by Partners are smaller in round 10, but are still above the free riding level, again contradicting the strategies hypothesis. |
|
Observation 4. The contributions by Strangers are greater that contributions by Partners in the last round. In round 10 the incentives are the same for both groups, and, moreover, they have had the same opportunity for learning. Nevertheless, Strangers invest significantly more, and free ride significantly less. This result does not support the learningn hypothesis. |
|
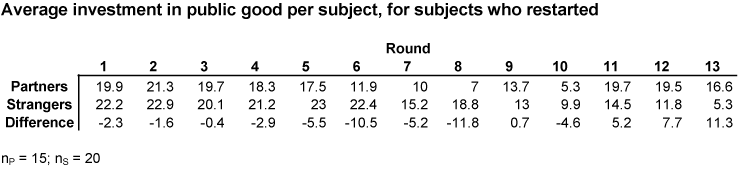
Observation 5. Strangers appear to be only temporarily affected by the restart. |
|
Observation 6. Partners return to high contributions after the restart. The restart also seems to have a lasting effect on this group. On the other hand, the Strangers were not affected as strongly and treated the restart as a continuation of the repeated single-shot game. Since the learning hypothesis predicts that both Partners and Strangers should be uneffected by the restart, it suggests that there might actually be little learning about free riding, and that subjects mostly understand the incentives from the start. As Andreoni notes, subjects given the opportunity to repeat their choices, they by and large do so. Hence, learning is also unlikely to provide an explanation of decrease in contributions towards the end of the game. |
|
Interpretation of Results and Possible Explanations |
|
Based on observations 1-6, both rational strategic play and learning hypotheses are contradicted in this study. Andreoni suggests that perhaps the hypotheses do not focus on the right kind of learning. It is possible that subjects have learned the single-shot dominant strategy, but have not learned the backward induction necessary to understand the equilibrium. Also an understanding of the single-shot equilibria does not necessarily reveal an understanding of the repeated-game structure. The results also suggest that one might want to consider an alternative to monetary payoff maximizing model, for example subjects getting non-monetary pleasure from cooperative outcomes or investing being consistent with social norms about participation in social dilemmas. Decay in this case might represent the groups' struggles to establish a norm. For further discussion on alternatives to monetary payoff maximizing model, see the section on Trust, Fairness, and Reciprocity. |
|
|
Page source: http://www.econport.org/econport/request?page=man_pg_experimentalresearch_whyfreeride
|